프론트엔드에 repository pattern 적용기 - 1
Repository pattern을 고려한 이유
- 관심사의 분리
백엔드에서는 DB나 다른 서버에서 데이터를 불러오는 영역을 repository layer라고 부르고 있으며 이는 당연한 구조로 받아들여진다.
프론트엔드에서도 데이터를 불러오는 코드가 있기 때문에 이 영역을 repository layer로 나눌 수 있다.
관심사 분리는 클린코드를 위해서 항상 염두해두어야 할 가치이다.
데이터를 불러오는 코드를 비지니스 로직과 분리하여 관리함으로써 로직에 더 집중할 수 있게된다.
- 테스트의 용이함 and 백엔드와의 접점 줄이기
Repository pattern을 도입한 가장 큰 이유이다.
프론트엔드는 백엔드가 준비가 되지 않으면 데이터를 불러와 화면을 구성할 수 없기 때문에 api가 완성되기를 기다리는 경우가 태반이다. 이 문제를 해결하고자 백엔드가 준비 되지 않았더라도 백엔드와 인터페이스만 맞추었다면 프론트엔드 독자적으로 mocking을 하면서 테스트를 할 수 있는 환경을 구성하고자 했다. 또한 비지니스 레이어에서 테스트 코드인지 실제 구현체 코드인지 알 지 못하고 repository layer와 인터페이스로 주고 받기를 원했다.
이를 통해 백엔드와의 응집도는 줄이면서 테스트 용이하게 개발 할 수 있는 환경을 제공할 수 있게된다.
Repostiroy pattern이란?
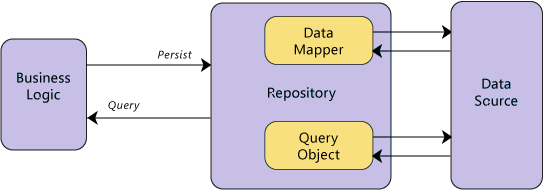
Repository Layer는 데이터에 대한 CRUD operation을 하고 data를 entity와 맵핑하는 역할을 한다. (entity는 data store에서 오는 값, data는 client business layer에서 사용되는 값)
Client business layer는 데이터가 어떤 데이터 소스에서 왔는지 어떤 구현체로 구현되어있는지 고려할 필요 없이 데이터를 가지고와 사용하기만 하면 된다.
DI의 필요
Repository layer를 구성하는데 있어서 DI가 필수적이다.
IUserRepository: UserRepository의 interface
TUserRepository: IUserRepository의 구현체로서 Mocking을 하고있는 테스트 구현체
UserRepository: IUserRepository의 구현체로서 서버와 통신하는 코드가 구현된 실 구현체
User 데이터를 사용하는 비지니스 레이어에서 구현체를 사용하게되면 구현체를 바꿀때마다 코드를 여러곳에서 수정해줘야 하는 번거로움이 생긴다. 따라서 비지니스 레이어에서는 구현체를 알아선 안되고 인터페이스만을 사용해야한다. 때문에 의존성을 주입해주고 사용하는 곳에선 인터페이스만 알수있도록 해야한다.
이를 위해 inversify라는 IoC 컨테이너를 사용하였다.
Next
댓글남기기